Matteo Ruggero Ronchi PhD & Postdoc @ CALTECH
Brief Bio

My research interests lie in the areas of Computer Vision and Robotics. In particular, I am interested in the task of estimating the pose (2D and 3D) of humans portrayed in pictures and studying how can that (i) be done if there is small availability of supervised training data, and (ii) be applied to the task of controlling the motor skills of robots.
I completed my PhD in Computer Science (2013-2019) and Postdoctoral studies in the Computational Vision Lab at Caltech, having enjoyed the great fortune of being advised by Pietro Perona.
Prior to that, I attended the University of Siena, in Italy, where I received both my Bachelor (2007-2010) and Master's (2010-2012) Degree in Computer Science and Information Engineering. During that period, I was fortunate to be supervised by Michelangelo Diligenti and Marco Gori and worked on the application of machine learning methods to the problems of Image Steganalysis and unsupervised Feature Learning for visual recognition.
Old Website (< 2013) New Website (> 2020)PhD Thesis
The underlying thread of my PhD Thesis is the investigation of new ways for enabling interactions between social robots and humans, by advancing the visual perception capabilities of robots when they process images and videos in which humans are the main focus of attention.
Thesis Link.Research Projects
How Much does Multi-View Self-Supervision Help 3D Pose Estimation?
3D pose estimation from a single image is challenging due to both the inherent ambiguity of the task and the difficulty of collecting large and varied supervised training datasets. Self-supervised learning has emerged as an alternative solution where the aim is to learn features that encode pose information without requiring explicit supervision. This feature learning step is typically framed as solving a pretext task that can capture information about human pose, such as temporal alignment of video frames or multi-view reconstruction. However, directly comparing current approaches is difficult due to different datasets and experimental settings used. In this paper we standardize this comparison by performing a detailed evaluation of multi-view self-supervised feature learning methods. Through experiments on Human3.6M, we observe several important issues that arise when using multi-view information as a training signal, including the impact of the amount of supervised pose data, the 3D reference frame used, the power of different pose decoders, among others. We conclude with recommendations and by highlighting open questions.

It's all Relative: Monocular 3D Human Pose Estimation from Weakly Supervised Data (BMVC'18)
We address the problem of 3D human pose estimation from 2D input images using only weakly supervised training data. Despite showing considerable success for 2D pose estimation, the application of supervised machine learning to 3D pose estimation in real world images is currently hampered by the lack of varied training images with associated 3D poses. Existing 3D pose estimation algorithms train on data that has either been collected in carefully controlled studio settings or has been generated synthetically. Instead, we take a different approach, and propose a 3D human pose estimation algorithm that only requires relative estimates of depth at training time. Such training signal, although noisy, can be easily collected from crowd annotators, and is of sufficient quality for enabling successful training and evaluation of 3D pose algorithms. Our results are competitive with fully supervised regression based approaches on the Human3.6M dataset, despite using significantly weaker training data. Our proposed approach opens the door to using existing widespread 2D datasets for 3D pose estimation by allowing fine-tuning with noisy relative constraints, resulting in more accurate 3D poses.
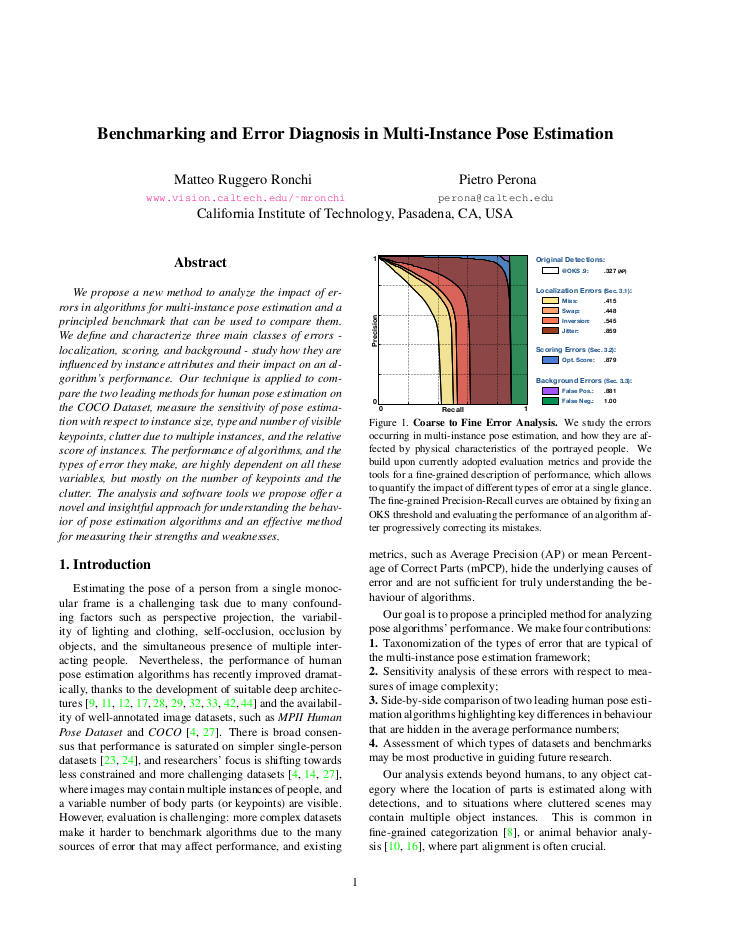
Benchmarking and Error Diagnosis in Multi-Instance Pose Estimation (ICCV'17)
We propose a new method to analyze the impact of errors in algorithms for multi-instance pose estimation and a principled benchmark that can be used to compare them. We define and characterize three main classes of errors - localization, scoring, and background - study how they are influenced by instance attributes and their impact on an algorithm's performance. Our technique is applied to compare the two leading methods for human pose estimation on the COCO Dataset, measure the sensitivity of pose estimation with respect to instance size, type and number of visible keypoints, clutter due to multiple instances, and the relative score of instances. The performance of algorithms, and the types of error they make, are highly dependent on all these variables, but mostly on the number of keypoints and the clutter. The analysis and software tools we propose offer a novel and insightful approach for understanding the behavior of pose estimation algorithms and an effective method for measuring their strengths and weaknesses.

A Rotation Invariant Latent Factor Model for Moveme Discovery from Static Poses (ICDM'16)
We tackle the problem of learning a rotation invariant latent factor model when the training data is comprised of lower-dimensional projections of the original feature space. The main goal is the discovery of a set of 3-D bases poses that can characterize the manifold of primitive human motions, or movemes, from a training set of 2-D projected poses obtained from still images taken at various camera angles. The proposed technique for basis discovery is data-driven rather than hand-designed. The learned representation is rotation invariant, and can reconstruct any training instance from multiple viewing angles. We apply our method to modeling human poses in sports (via the Leeds Sports Dataset), and demonstrate the effectiveness of the learned bases in a range of applications such as activity classification, inference of dynamics from a single frame, and synthetic representation of movements.

Describing Common Human Visual Actions in Images (BMVC'15)
Which common human actions and interactions are recognizable in monocular still images? Which involve objects and/or other people? How many is a person performing at a time? We address these questions by exploring the actions and interactions that are detectable in the images of the MS COCO dataset. We make two main contributions. First, a list of 140 common ‘visual actions’, obtained by analyzing the largest on-line verb lexicon currently available for English (VerbNet) and human sentences used to describe images in MS COCO. Second, a complete set of annotations for those ‘visual actions’, composed of subject-object and associated verb, which we call COCO-a (a for ‘actions’). COCO-a is unique because it is data-driven, rather than experimenter-biased, and all subjects and objects are localized. A statistical analysis of the accuracy of our annotations and of each action, interaction and subject-object combination is provided.

Distance Estimation of an Unknown Person from a Portrait (ECCV'14)
We propose the first automated method for estimating distance from frontal pictures of unknown faces. Camera calibration is not necessary, nor is the reconstruction of a 3D representation of the shape of the head. Our method is based on estimating automatically the position of face and head landmarks in the image, and then using a regressor to estimate distance from such measurements. We collected and annotated a dataset of frontal portraits of 53 individuals spanning a number of attributes (sex, age, race, hair), each photographed from seven distances. We find that our proposed method outperforms humans performing the same task. We observe that different physiognomies will bias systematically the estimate of distance, i.e. some people look closer than others. We explore which landmarks are more important for this task.
Extra
Contact me
If you'd like to get in touch, use one of the following:
Email LinkedIn Github Google Scholar