Distance Estimation of an Unknown Person from a Portrait ECCV'14
Introduction
Consider a standard portrait of a person – either painted or photographed. Can one estimate the distance between the camera (or the eye of the painter) and the face of the sitter? Can one do so accurately even when the camera and the sitter are unknown?

We propose the first automated method for estimating the camera-subject distance from a single frontal picture of an unknown sitter. Camera calibration is not necessary, nor is the reconstruction of a 3D representation of the shape of the subject's head. Our method is divided into two steps: firstly we automatically estimate the location and shape of the subject's face in an image, characterized by 55 costum keypoints positioned on eyes, eyebrows, nose, mouth, head and harline contour. Secondly we train a regressor to estimate the absolute distance from the measurement of changes in the position of these landmarks due to the effect of perspective in images taken at different distances (sometimes informally called "Perspective Distortion").
We collected and annotated a dataset of frontal portraits of 53 individuals spanning a number of attributes such as sex, age, ethnicity and hairstyle, each photographed from seven distances - 2, 3, 4, 6, 8, 12 and 16 ft. The proposed method exploits the high correlation between "perspective distortion" and absolute distance and outperforms humans in the tasks of 1) purely estimating the absolute distance and 2) reordering portraits of faces taken at different distances. We observed the phenomenon that different physiognomies will bias systematically the estimate of distance, i.e. some people look closer than others. We explored the importance of individual landmarks in the execution of both task.
Contributions
-
A novel approach for estimating the camera-subject distance from a single 2D portrait photograph when both the camera and the sitter are unknown. Our method yields useful signal and outperforms humans on two complex tasks.
-
The introduction of a new dataset of portraits, Caltech Multi-Distance Portraits (CMDP), composed of 53 subjects belonging to both sexes and a variety of ages, ethnic backgrounds and physiognomies. Each subject was photographed from seven different distances and each portrait manually labeled with 55 keypoints distributed across the sitter's head and face. The dataset is publicly available, see the CMDP section.
-
An in-depth analysis and discussion on the feasibility of the proposed approach. We tackled two different variants of the distance estimation task (classification and regression) and explored what are the most important input visual cues. We studied our method's performances when using both automatically estimated and ground-truth human annotated landmarks. Finally, we compared our results with the performances of human observers on the same tasks. Interestingly, we discovered that the main source of error for both humans and our method is the variability of faces' physiognomies.
Results
REORDERING TASK
REGRESSION TASK
PHYSIOGNOMY FINDINGS
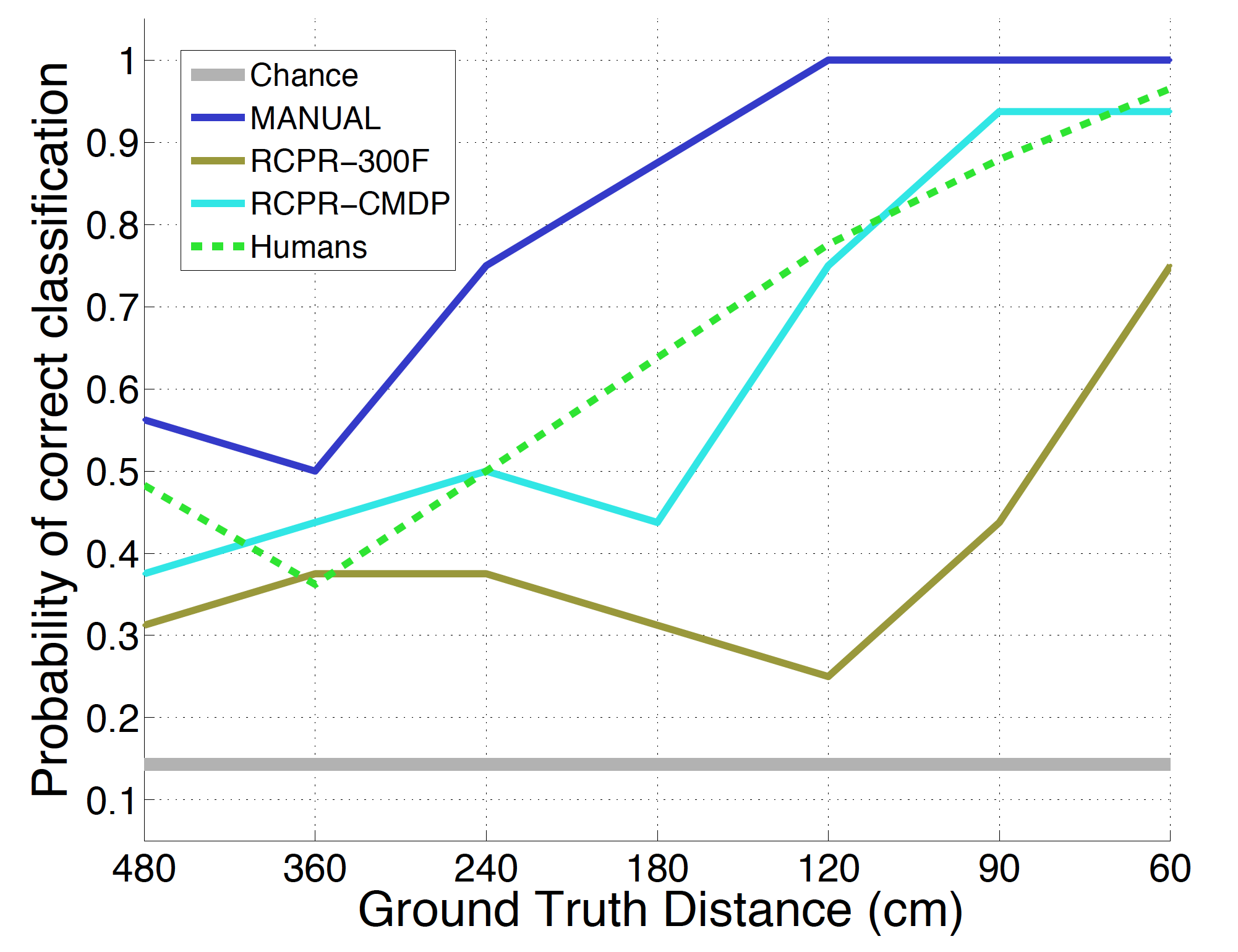
We show the results obtained by three variants of our method and by humans asked to perform the exact same task of sorting a random permutation of all 7 pictures of a subject based on their conveyed distance. The ground-truth landmarks based variant (MANUAL) outperforms human performance by 16%, while the automatic based ones (RCPR-CMDP and RCPR-300F) are slightly behind by 3% and 25% respectively. Closer faces appear to be much easier to classify than distant ones because of their unusual and disproportioned geometry. This has been confirmed by the human subjects of the study, stating their difficulty in telling apart images in the middle distance-range. Our best variant outperforms human capabilities in the classification task, correctly reordering an average of 81% of the faces when random chance is merely 15%. The same method using machine estimated landmarks still classifies correctly 62% of the images, and could very likely be improved just by increasing the availability of training examples.
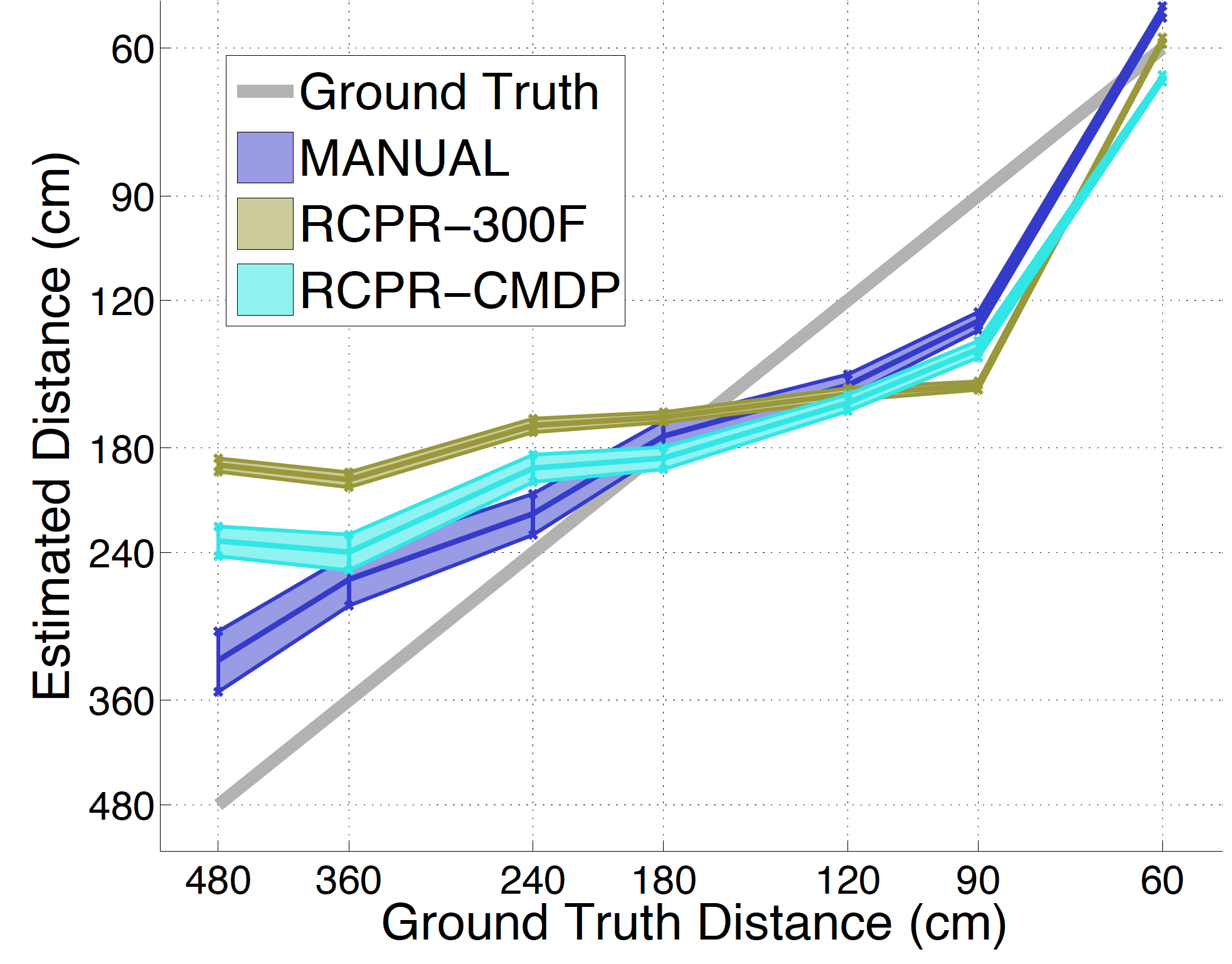
There is a strong correlation between ground-truth distances and predictions of our method. MANUAL achieves 75% correlation with a coefficient of determination of R2 = .5, while RCPR-CMDP and RCPR-300F achieve 65% and 45% correlation and R2 = .48 and .46 respectively. All variants seem to struggle more with the larger distances, as noticeable from the higher variance and greater distance to ground truth. This is an expected result considering the lower effect of perspective differences between two images taken from afar. As expected, directly estimating the distance of an unknown face proved to be a harder task. Nonetheless, a correlation of 75% with ground-truth indicates that the method is learning well.
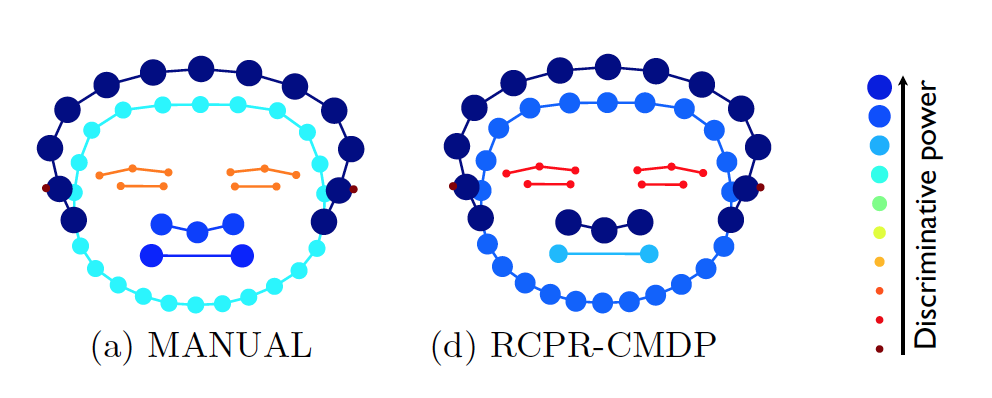
We measured how well each landmark group (head contour, face contour, eyes, nose, mouth) compares to best performance when only that particular group is used. For both MANUAL and RCPR-CMDP, in the classification task, best results are achieved using the head contour and the nose, while the eyes seem to be the least useful.
Also in the regression task, for both MANUAL and RCPR-CMDP, the most discriminative landmark group is the nose.
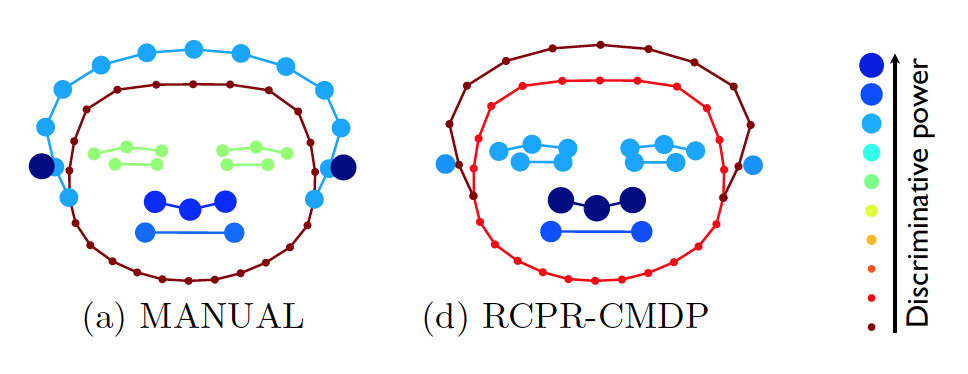
Discriminative power on these tasks is quantified as how well the method performed when incorporating those input landmarks into the learning. These findings agree with human annotators, which consistently reported during their psychophysics experiments that the use of the deformation in a subject’s nose was the most informative visual cue.
CMDP Dataset
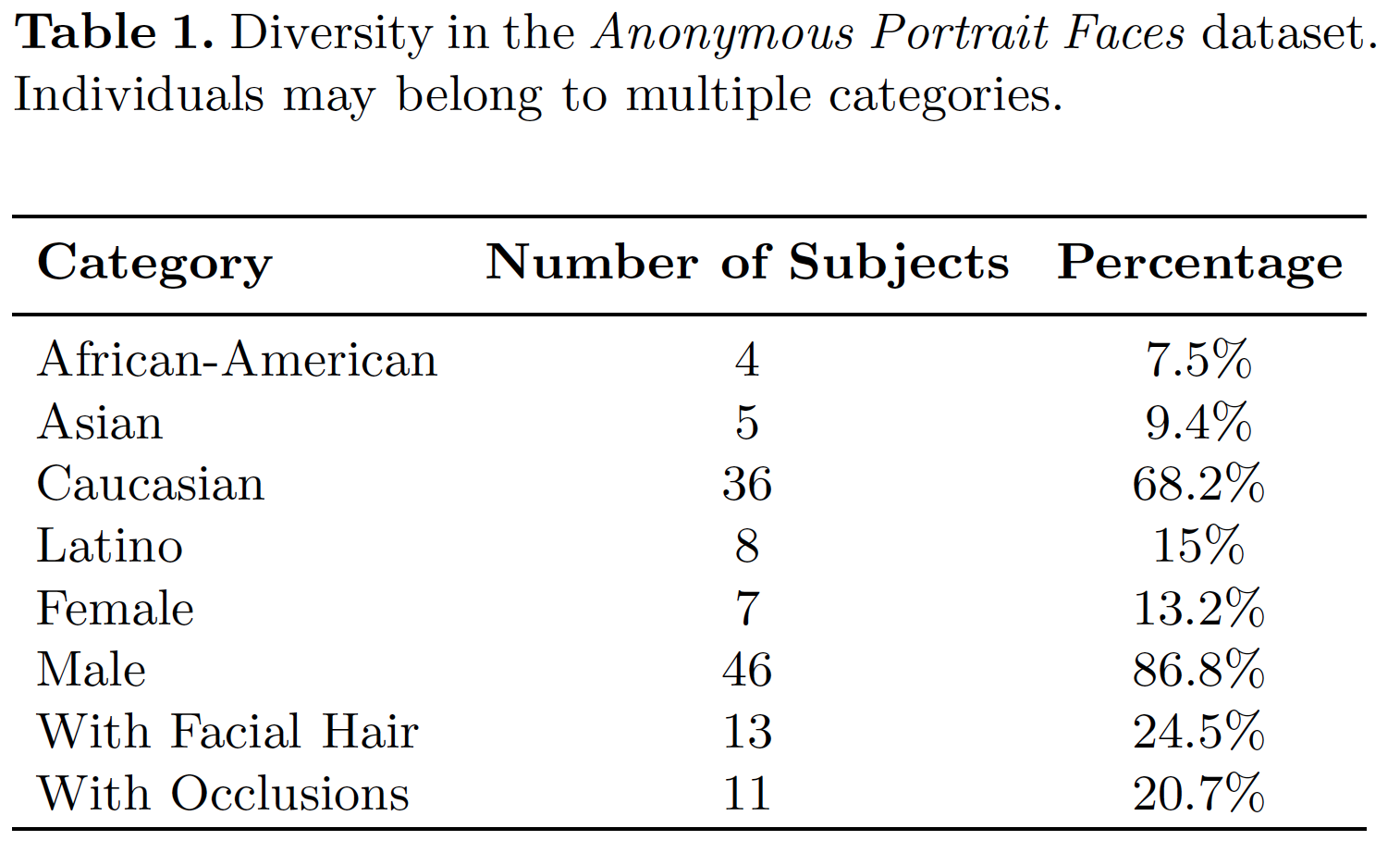
We collected a novel dataset, the Caltech Multi-Distance Portraits (CMDP). This collection is made of high quality frontal portraits of 53 individuals against a blue background imaged from seven distances spanning the typical range of distances between photographer and subject: 2, 3, 4, 6, 8, 12, 16 ft (60, 90, 120, 180, 240, 360, 480 cm). For distances exceeding 5m, perspective projection approaches a parallel projection (the depth of a face is about 10cm), therefore no samples beyond 480 cm were needed. Participants were selected among both genders, different ages and a variety of ethnicities, physiognomies, hair and facial hair styles, to make the dataset as heterogeneous and representative as possible.

Pictures were shot with a Canon Rebel Xti DSLR camera mounting a 28-300mm L-series Canon zoom lens. Participants standing in front of a blue background were instructed to remain still and maintain a neutral expression. The photographer used a monopod to support the camera-lens assembly. The monopod was adjusted so that the height of the center of the lens would correspond to the bridge of the nose, between the eyes. Markings on the ground indicated seven distances. After taking each picture, the photographer moved the foot of the monopod to the next marking, adjusted the zoom to fill the frame of the picture with the face, and took the next picture. This procedure resulted in seven pictures (one per distance) being taken within 15-20 seconds. Images were then cropped and resampled to a common format. The lens was calibrated at different zoom settings to verify the amount of barrel distortion, which was found to be very small at all settings, and thus left uncorrected. Lens calibration was then discarded and not used further in our experiments.
All images in the dataset were manually annotated by three human annotators with 55 facial landmarks distributed over and along the face and head contour. To check consistency of annotations, randomly selected images from different subjects were doubly annotated. Annotators resulted to be very consistent, showing an average disagreement between them smaller than 3% of the interocular distance, and not varying much across distances. The location of the custom keypoints is very different from the positions typically used in literature, more focused towards the center and bottom of the face, as for example Multi-pie format. We purposely wanted to have landmarks around the head contour and all around the face, to sample a larger area of the face.
Download
The following buttons will download the CMDP dataset fully annotated and the Matlab code for visualizing the results of the landmark estimation algorithm (RCPR) on the CMDP dataset and reproducing the paper's results on both the classification and regression tasks. Full details are described in the README file.
Notes:- Code Version [1.0.0].
- Dataset Version [2.0.0]: 51 subjects, 7 distances, 3 annotation types (Manual, RCPR-CMDP, RCPR-300F), pictures in original and standardized version for each annotation type.
- RCPR-CMDP annotations are available only for the 16 subjects in the test set. Soon we will release them for the full dataset.
- Piotr Dollar's Image & Video Matlab Toolbox is a required external library.
- This code is licensed under the Simplified BSD License.
Cite
If you find our paper or the released data or code useful to your work, please cite:
@incollection{ perona2014PortraitDistanceEstimation, title={Distance Estimation of an Unknown Person from a Portrait}, author={Xavier P. Burgos-Artizzu, Matteo Ruggero Ronchi and Pietro Perona}, booktitle={Computer Vision--ECCV 2014}, pages={313--327}, year={2014}, publisher={Springer}, doi={10.1007/978-3-319-10590-1_21}}