Describing Common Human Visual Actions in Images BMVC'15
Introduction
The idea that actions are an important component of scene understanding in computer vision dates back at least to the '80s. In order to detect actions alongside objects the relationships between those objects needs to be discovered. For each action the roles of `subject' (active agent) and `object' (passive - whether thing or person) have to be identified. This information may be expressed as a `semantic network', which is the first useful output of a vision system for scene understanding.
Three main challenges face us in approaching scene understanding:
- Deciding the nature of the representation that needs to be produced (e.g. there is still disagreement on whether actions should be viewed as arcs or nodes in the semantic network).
- Designing algorithms that will analyze the image and produce the desired representation.
- Learning -- most of the algorithms that are involved have a considerable number of free parameters.
The ideal dataset to guide our next steps has four desiderata:
- It is representative of the pictures we collect every day.
- It is richly and accurately annotated with the type of information we would like our systems to know about.
- It is not biased by a particular approach to scene understanding, rather it is collected and annotated independently of any specific computational approach.
- It is large, containing sufficient data to train the large numbers of parameters that are present in today's algorithms.
In the present study we focus on actions that may be detected from single images (rather than video). We explore the visual actions that are present in the recently collected MS COCO image dataset. The MS COCO dataset is large, finely annotated and focussed on 81 commonly occurring objects and their typical surroundings.
Contributions
-
An unbiased method for estimating actions, where the data tells us which actions occur, rather than starting from an arbitrary list of actions and collecting images that represent them. We are thus able to explore the type, number and frequency of the actions that occur in common images. The outcome of this analysis is Visual VerbNet (VVN), listing the 140 common actions that are visually detectable in images.
-
A large and well annotated dataset of actions on the current best image dataset for visual recognition, with rich annotations including all the actions performed by each person in the dataset, and the people and objects that are involved in each action, subject's posture and emotion, and high level visual cues such as mutual position and distance. The dataset is publicly available, see the Download section.
Framework
We call visual action an action, state or occurrence that has a unique and unambiguous visual connotation, making it detectable and classifiable; i.e., lay down is a visual action, while relax is not. A visual action may be discriminable only from video data, multi-frame visual action such as open and close, or from monocular still images, single-frame visual action (simply visual action), such as stand, eat and play tennis. In order to label visual actions we will use the verbs that come readily to mind to a native English speaker, a concept akin to entry-level categorization for objects. Based on this criterion sometimes we prefer more general visual actions (e.g. play tennis) rather than the sports domain specific ones such as volley or serve, and drink rather than more specific motions such as lift a glass to the lips, other times more specific ones (e.g. shaking hands instead of more generally greet).
While taxonomization has been adopted as an adequate means of organizing object categories (e.g. animal → mammal → dog → dalmatian), and shallow taxonomies are indeed available for verbs in VerbNet, we are not interested in fine-grained categorization for the time being and do not believe that MS COCO would support it either. Thus, there are no taxonomies in our set of visual actions.
Coco-a Dataset
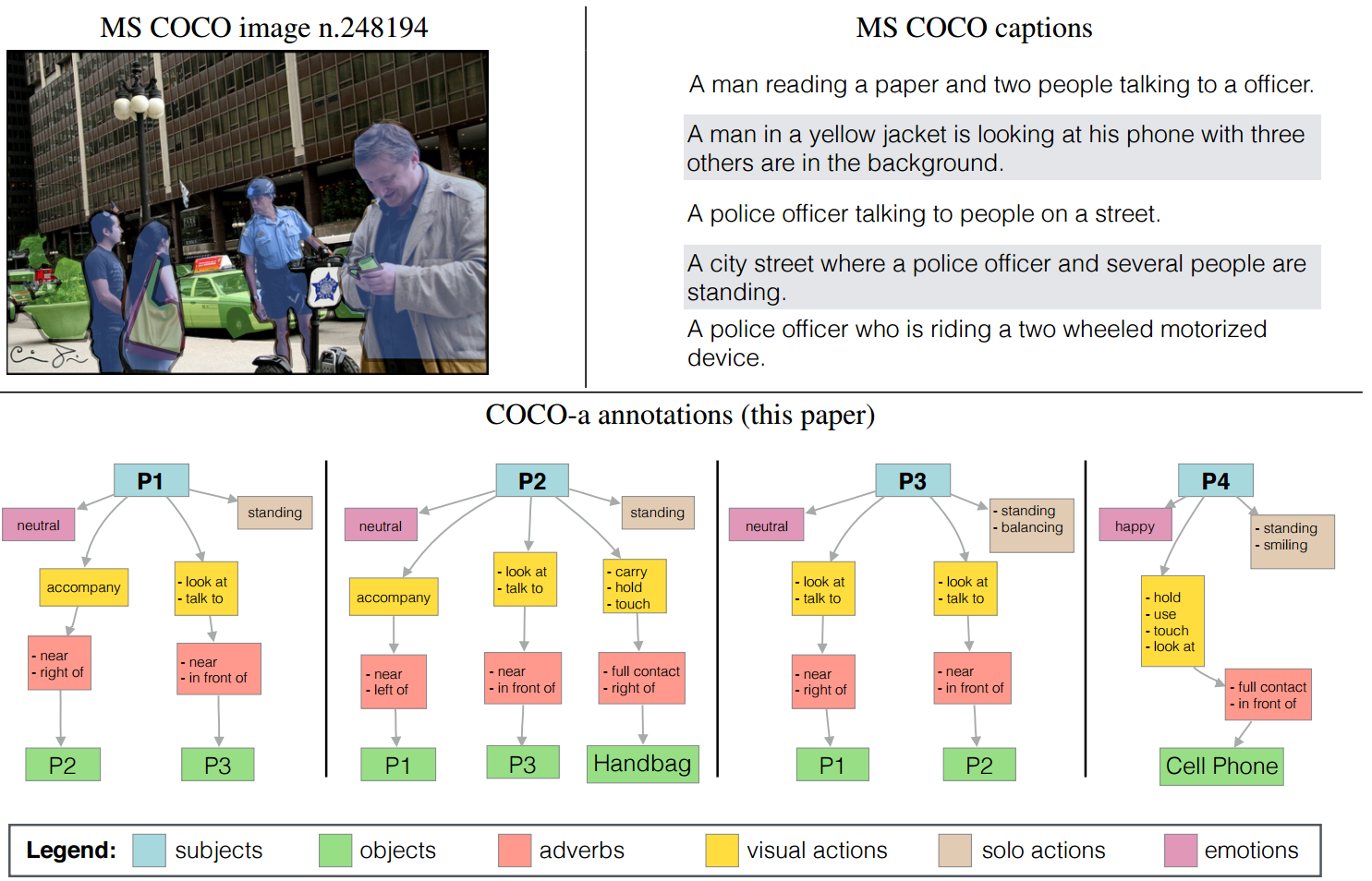
Our goal is to collect an unbiased dataset with a large amount of meaningful and detectable interactions involving human agents as subjects. We put together a process, exemplified in the Figure below, consisting of four steps.

1) Visual VerbNet
We obtained the list of common visual actions that are observed in everyday images, by a combined analysis of VerbNet and MS COCO captions. Our list, which we call Visual VerbNet attempts to include all actions that are visually discriminable. It avoids verb synonyms, actions that are specific to particular domains, and fine-grained actions. Unlike previous work, Visual VerbNet is not the result of experimenter’s idiosyncratic choices; rather, it is derived from linguistic analysis (VerbNet) and an existing large dataset of descriptions of everyday scenes (MS COCO Captions).
2) Image and Subject Selection
Different actions usually occur in different environments, so in order to balance the content of our dataset we selected an approximately equal number images of three types of scenes: sport, outdoor and indoor. We also selected images of various complexity, containing single subjects, small groups (2-4 subjects) and crowds (> 4 subjects). Next, we identified who is carrying out actions (the subjects), as all the people in an image whose pixel area is larger than 1600 pixels. All the people, regardless of size, are still considered as possible objects of an interaction.
3) Interactions Annotation
For each subject we identified the objects that he/she is interacting with, based on the agreement of 3 out of 5 Amazon Mechanical Turk annotators asked to evaluate each image.
4) Visual Actions Annotation
For each subject-object pair (and each single agent), we labelled all the possible actions and interactions involving that pair, along with high level visual cues such as emotion and posture of the subject, and spatial relationship and distance with the object of interaction (when present). We asked 3 annotators to select all the visual actions and adverbs that describe each subjet-object interaction pair. In some cases annotators interpreted interactions differently, but still correctly, so we return all the visual actions collected for each interaction along with the value of agreement of the annotators, rather than forcing a deterministic, but arbitrary, ground truth.
Analysis
In the figure below we can see the most frequent types of actions carried out when subjects interact with four specific object categories: other people, animals, inanimate objects (such as a handbag or a chair) and food. For interactions with people the visual actions belong mostly to the category ‘social’ and ‘perception’. When subjects interact with animals the visual actions are similar to those with people, except there are fewer ‘social’ actions and more ‘perception’ actions. Person and animal are the only types of objects for which the ‘communication’ visual actions are used at all. When people interact with objects the visual actions used to describe those interactions are mainly from the categories ‘with objects’ and ‘perception’. As expected, food items are the only ones that have ‘nutrition’ visual actions.

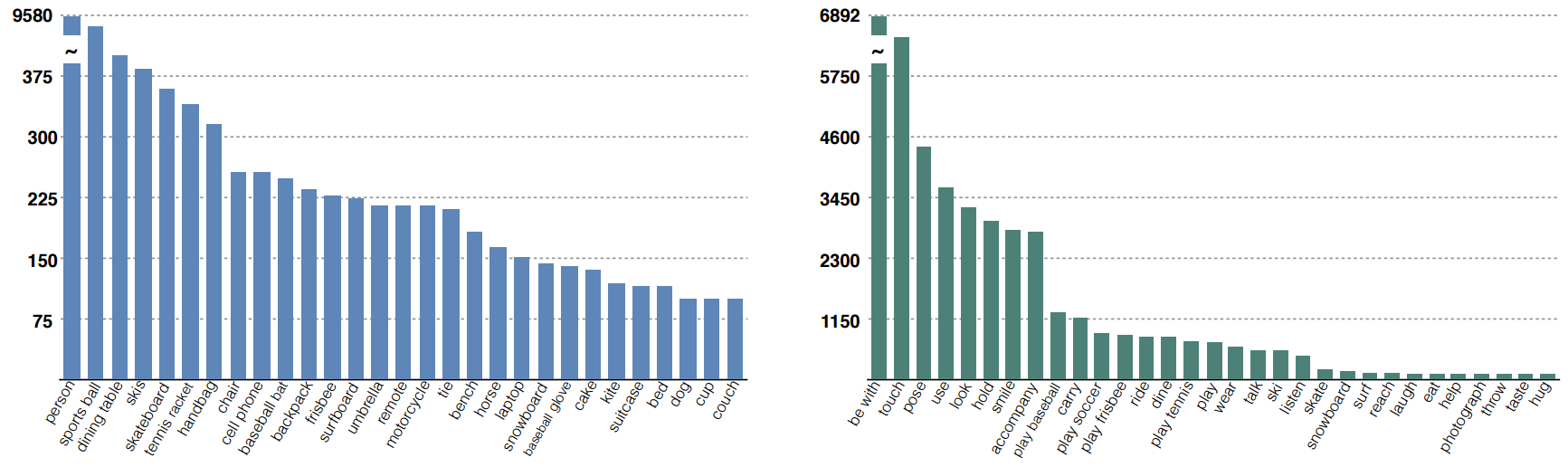
We show the 29 objects that people interact with (left) and the 31 visual actions that people perform (right) in the COCO-a dataset, having more than 100 occurrences. The human-centric nature of our dataset is confirmed by the fact that the most frequent object of interaction is other persons, an order of magnitude more than the other objects. Since our dataset contains an equal number of sports, outdoor and indoor scenes, the list of objects is heterogeneous and contains objects that can be found in all environments. It appears that the visual actions list has a very long tail, which leads to the observation that MS COCO dataset is sufficient for a thorough representation and study of about 20 to 30 visual actions. The most frequent visual action in our dataset is ‘be with’. This is a very particular visual action as annotators use it to specify when people belong to the same group. Common images often contain multiple people involved in different group actions, and this annotation can provide insights in learning concepts such as the difference between proximity and interaction – i.e. two people back to back are probably not part of the same group although spatially close.
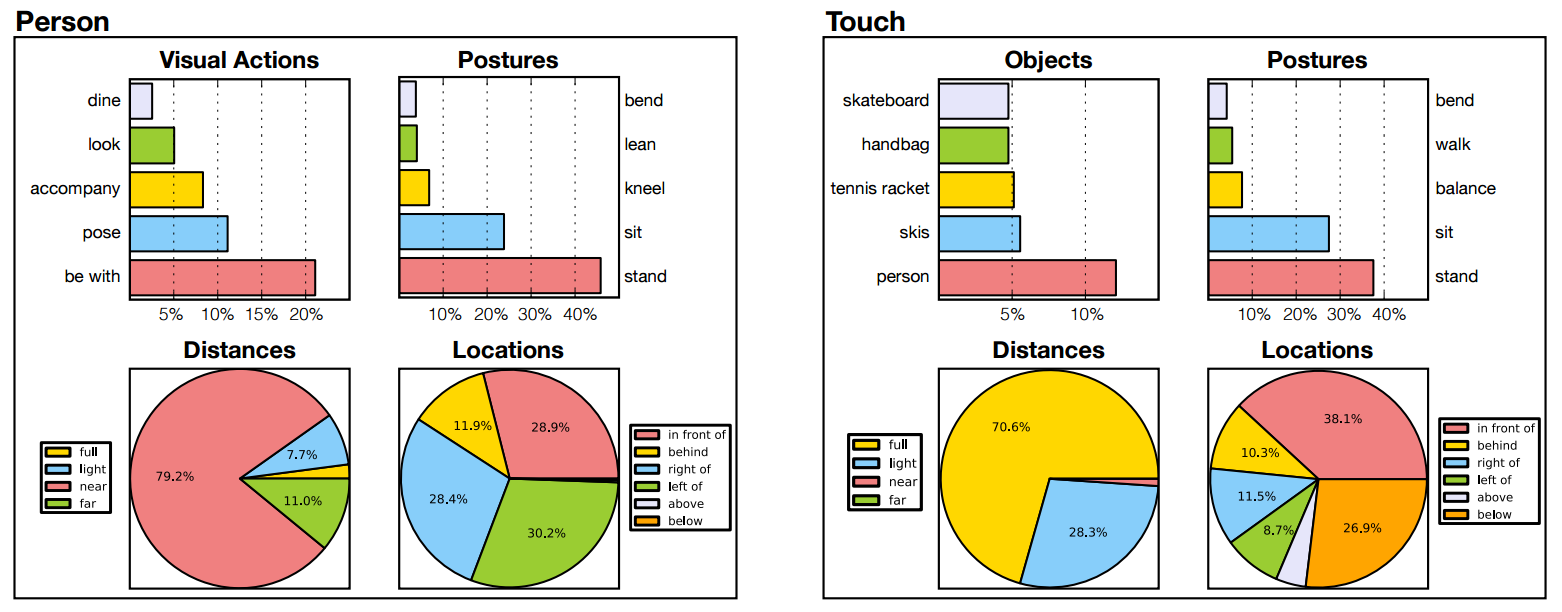
The COCO-a dataset contains a rich set of annotations. We provide two examples of the information that can be extracted and explored, for an object and a visual action contained in the dataset. The figure below on the left describes interactions between people. We list the most frequent visual actions that people perform together, postures that are held, distances of interaction and locations. A similar analysis can be carried out for the visual action touch, (on the right).
To explore the expressive power of our annotations we decided to query rare types of interactions and visualize the images retrieved. The figure below shows the result of querying our dataset for visual actions with rare emotion, posture, position or location combinations. The format of the annotations allows to query for images by specifying at the same time multiple properties of the interactions and their combinations, making them particularly suited for the training of image retrieval systems.

Download - (Beta Version Available!)
Click here to request the credentials for the latest Coco-a version, and to receive all the updates on the status of the Dataset.
Notes:- Api coming soon, click here for a demo.
- Visual VerbNet Version [1.0].
- Coco-a Dataset Version [0.9-beta].
- MS COCO api and annotations are required external library and data.
- This code and data is licensed under the Simplified BSD License.
Cite
If you find our paper or the released data or code useful to your work, please cite:
@inproceedings{ BMVC2015_52, title={Describing Common Human Visual Actions in Images}, author={Matteo Ruggero Ronchi and Pietro Perona}, year={2015}, month={September}, pages={52.1-52.12}, articleno={52}, numpages={12}, booktitle={Proceedings of the British Machine Vision Conference (BMVC)}, publisher={BMVA Press}, editor={Xianghua Xie, Mark W. Jones, and Gary K. L. Tam}, doi={10.5244/C.29.52}, isbn={1-901725-53-7}, url={https://dx.doi.org/10.5244/C.29.52}}