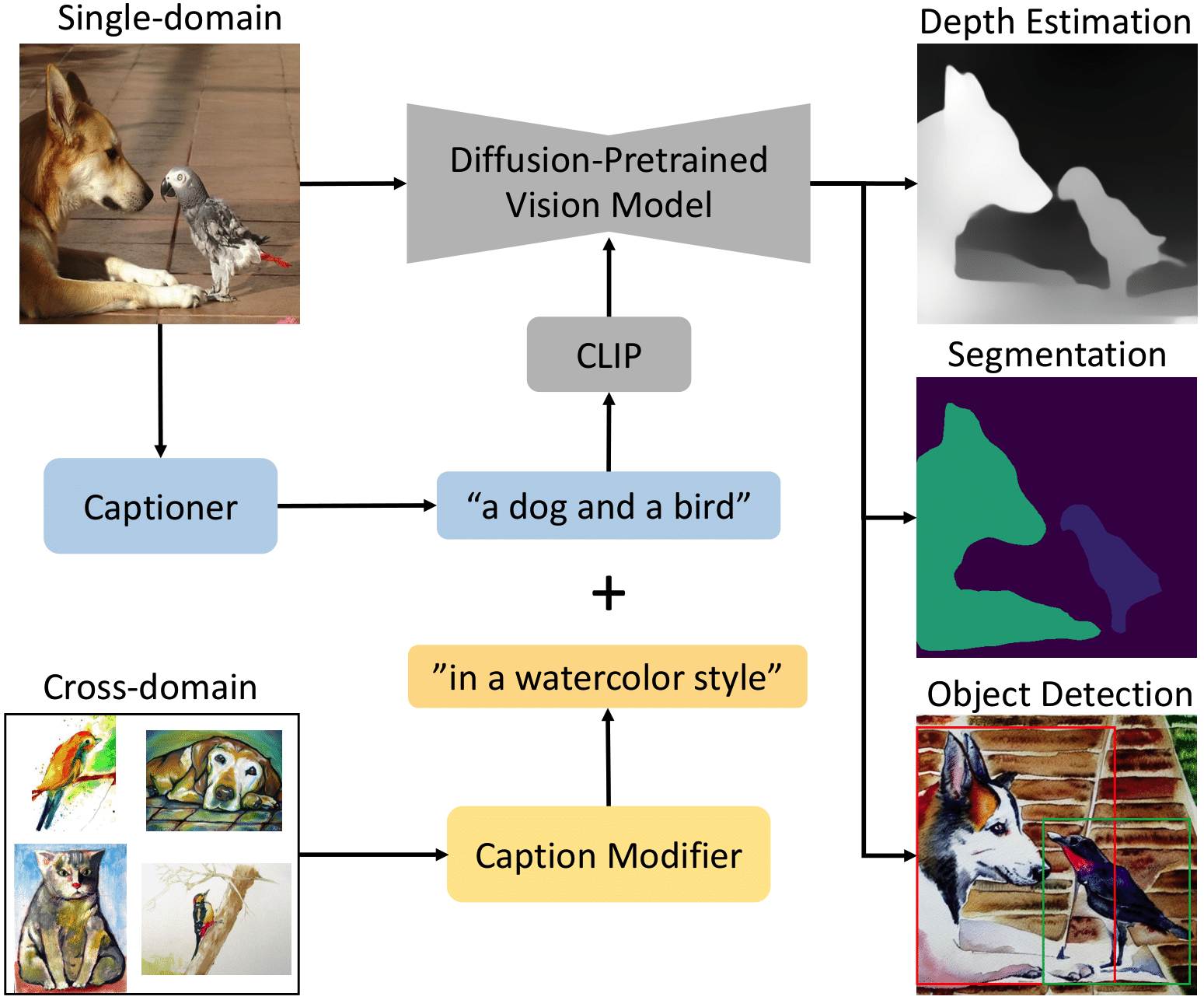
Pre-trained diffusion models have been used to boost accuracy in visual perception tasks, such
as semantic
segmentation and monocular depth estimation — the attention maps generated by the
diffusion model play
a pivotal role in enhancing the efficacy of task-specific heads.
What role does the diffusion model's prompt play? What is the best way to optimize it? We
investigate these
questions and find that automatically generated captions can improve text-image alignment and
significantly
enhance a model's cross-attention maps, leading to better perceptual performance. Our approach
improves upon
the current SOTA in diffusion-based semantic segmentation for ADE20K, improving 1.7 mIoU (+3.2%)
and the
current overall SOTA in depth estimation by 0.2 RMSE (+8%) on NYUv2.
Additionally, we find that captions help in cross-domain adaptation when we align text prompts
to the target
domain. Our object detection method, trained on Pascal VOC2012, achieves SOTA results on
Watercolor2K and
Comic2K. Our segmentation method, trained on Cityscapes, achieves SOTA results on the Dark
Zurich and
Nighttime Driving benchmarks.
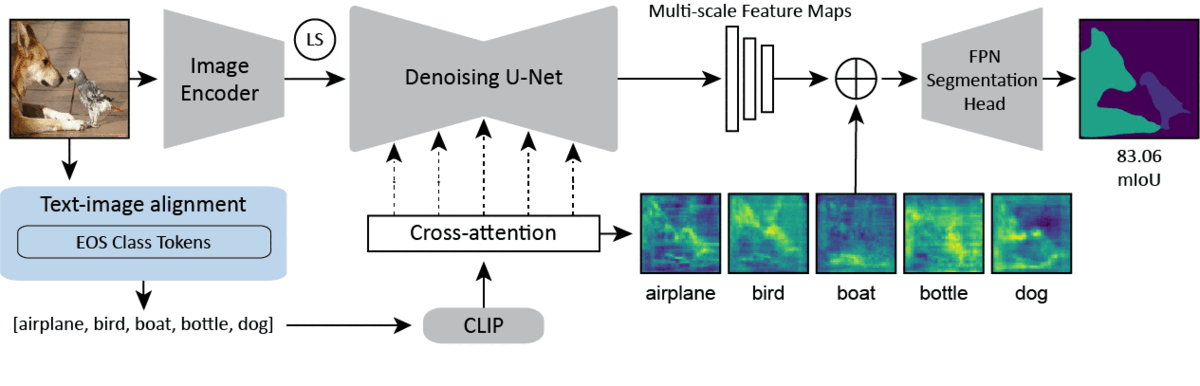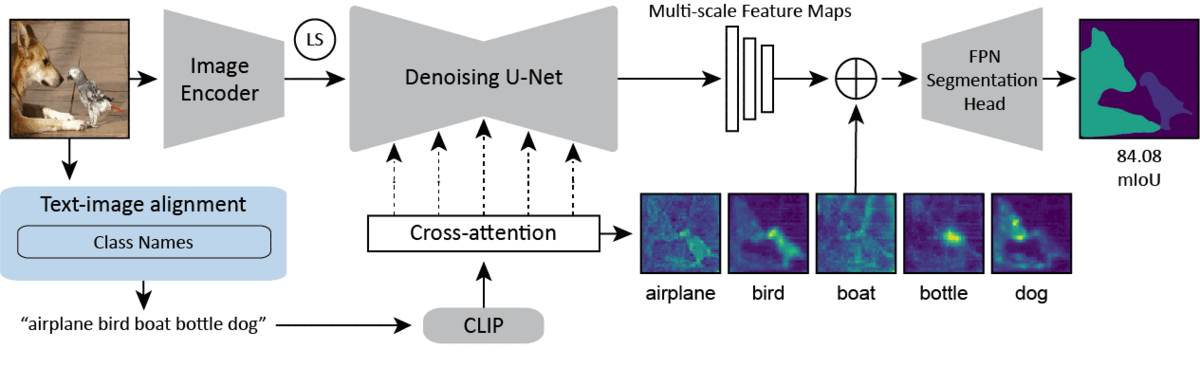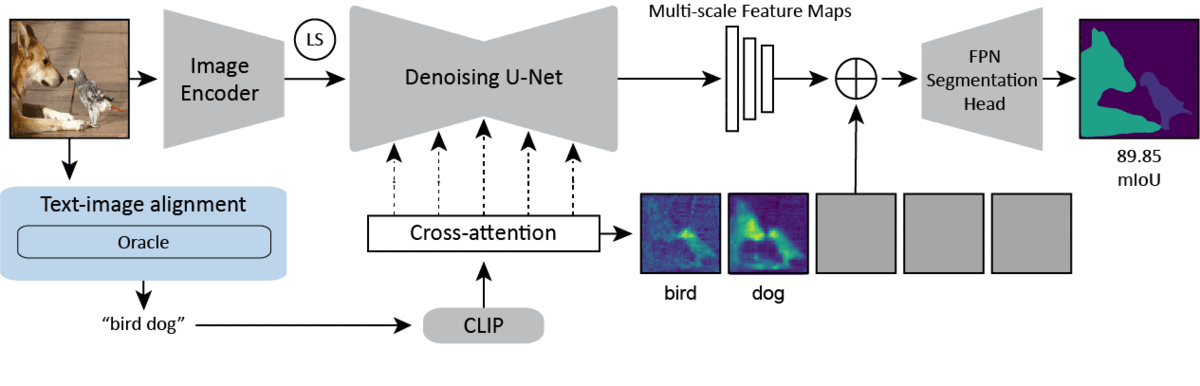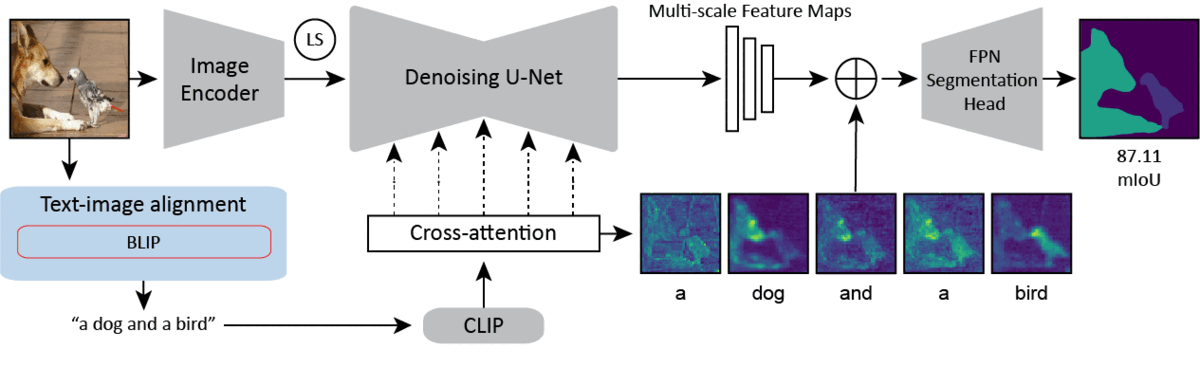
Overview of our single-domain method. Our method makes use of the stable diffusion backbone. We encode an image into its latent representation and pass it through a single step of the diffusion model. We concatenate the cross-attention maps, the multi-scale feature maps, and the latent code for the image (not shown), before passing them to the vision specific decoder. In the blue box, we show various captioning/prompting strategies with differing levels of text-image alignment. We find that increasing alignment significantly improves performance. Our best performing method (excluding an Oracle method) uses BLIP-2 to caption the image and feeds the caption to the backbone as the prompt.

Overview of our cross-domain method. Starting from our best single-domain alignment method (captioning with BLIP-2), we modify the caption to improve alignment with the target domain. We try several methods, from simple text to more powerful model personalization strategies. Model personalization strategies take a random sample of images and learn to generate images that are similar. We find that personalizing the model to the target domain as a pre-training step (with unlabeled target domain images) improves generalization to the target domain.
We analyze the effects of different prompting strategies. We qualitatively explore the effect of off-target classes using an image-to-image variation pipeline on a pretrained Stable Diffusion backbone. Then, we quantitatively measure the effect of off-target classes on our Oracle model. We find that off-target classes have a significant effect on the Oracle model, and that the effect is picked up by the task-specific head.


Qualitative image-to-image variation analysis. We use the image to image (img2img) variation pipeline (with Stable Diffusion 1.5 weights) to qualitatively analyze the effects of prompts with off-target classes. In the gif, we generate an image variation of the original image at differing strength ratios. On the left we show the Class Names prompt, which is simply a string of class names. On the right we use an aligned BLIP prompt. The effect of off-target classes is most clear in stronger variations in which objects belonging to off-target classes (a potted plant or a sofa) become more prominent. These qualitative results imply that this kind of prompt modifies the latent representation to incorporate information about off-target classes, potentially making the downstream task more difficult. In contrast, using the BLIP prompt changes the image, but the semantics (position of objects, classes present) of the image variation are significantly closer to the original. These results suggest a mechanism for how off-target classes may impact our vision models. In the next analysis, we quantitatively measure this effect using a fully trained Oracle model.
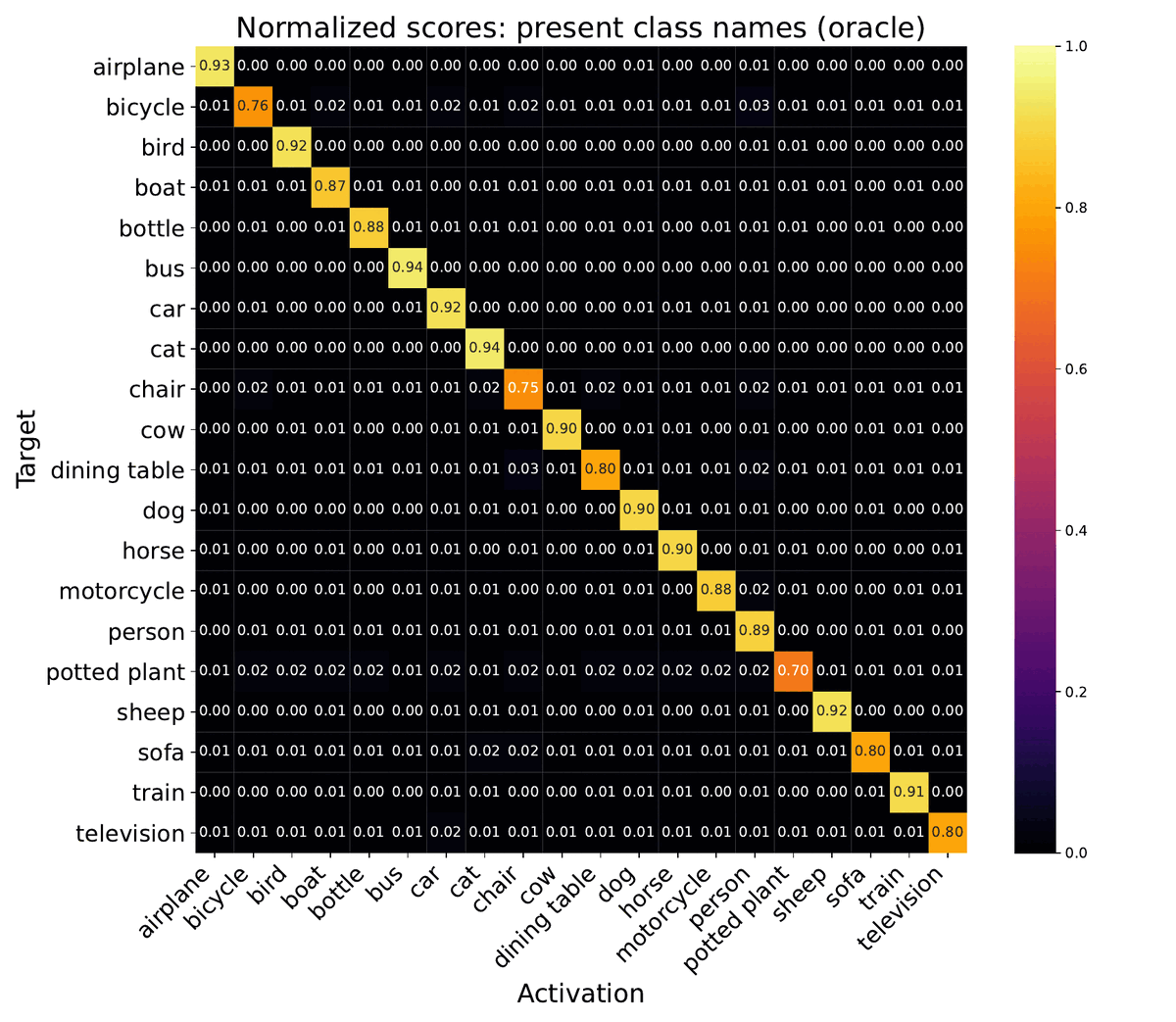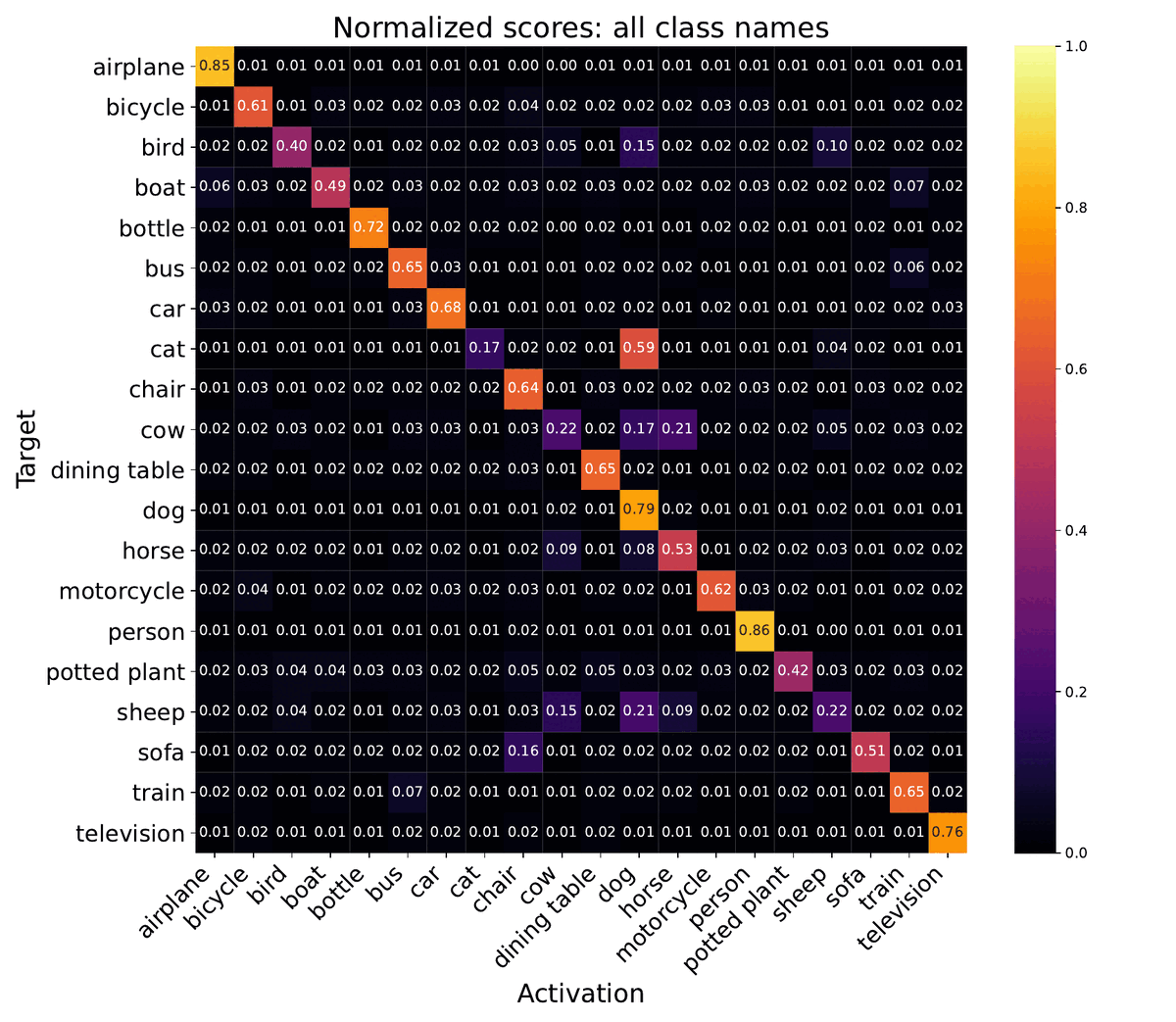
Quantitative effect of Class Names on Oracle model. To quantify the impact of the off-target classes on the downstream vision task, we measure the averaged pixel-wise scores (normalized via Softmax) per class when passing the class names to the Oracle segmentation model for Pascal VOC 2012. We compare this to the original oracle prompt. We find that including the off-target prompts significantly increases the probability of a pixel being misclassified as one of the semantically nearby off-target classes. For example, if the original image contains a cow, including the words dog and horse significantly raises the probability of mis-classifying the pixels belonging to the cow as pixels belonging to a dog or a horse. These results indicate that the effect of off-target classes is picked up by the task-specific head and is incorporated into the output.
Qualitative examples of Dreambooth and Textual Inversionfor Cross-Domain We show examples of images generated with Dreambooth and Textual Inversion in target datasets: Dark Zurich, Comic2k, Watercolor2k. They are qualitatively similar to images from the real datasets, indicating that the learned tokens are able to capture the style of the target domains. These tokens (and thie backbone for DreamBooth) are used in our alignment strategy for the cross-domain experiments.
 Textual inversion and Dreambooth tokens of Cityscapes to Dark Zurich
Textual inversion and Dreambooth tokens of Cityscapes to Dark Zurich Textual inversion and Dreambooth tokens of VOC to Comic
Textual inversion and Dreambooth tokens of VOC to Comic Textual inversion and Dreambooth tokens of VOC to Watercolor2k
Textual inversion and Dreambooth tokens of VOC to Watercolor2k
@article{kondapaneni2024tadp,
title={Text-Image Alignment for Diffusion-Based Perception},
author={Kondapaneni, Neehar and Marks, Markus and Knott, Manuel and Guimaraes, Rogerio and Perona, Pietro},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024},
month={June},
pages={13883-13893}
}