Less is More: Discovering Concise Network Explanations (DCNE)

Abstract
We introduce Discovering Conceptual Network Explanations (DCNE), a new approach for generating human-comprehensible visual explanations to enhance the interpretability of deep neural image classifiers. Our method automatically finds visual explanations that are critical for discriminating between classes. This is achieved by simultaneously optimizing three criteria: the explanations should be few, diverse, and human-interpretable. Our approach builds on the recently introduced Concept Relevance Propagation (CRP) explainability method. While CRP is effective at describing individual neuronal activations, it generates too many concepts, which impacts human comprehension. Instead, DCNE selects the few most important explanations. We introduce a new evaluation dataset centered on the challenging task of classifying birds, enabling us to compare the alignment of DCNE's explanations to those of human expert-defined ones. Compared to existing eXplainable Artificial Intelligence (XAI) methods, DCNE has a desirable trade-off between conciseness and completeness when summarizing network explanations. It produces 1/30 of CRP's explanations while only resulting in a slight reduction in explanation quality. DCNE represents a step forward in making neural network decisions accessible and interpretable to humans, providing a valuable tool for both researchers and practitioners in XAI and model alignment.
Measuring Alignment to Humans
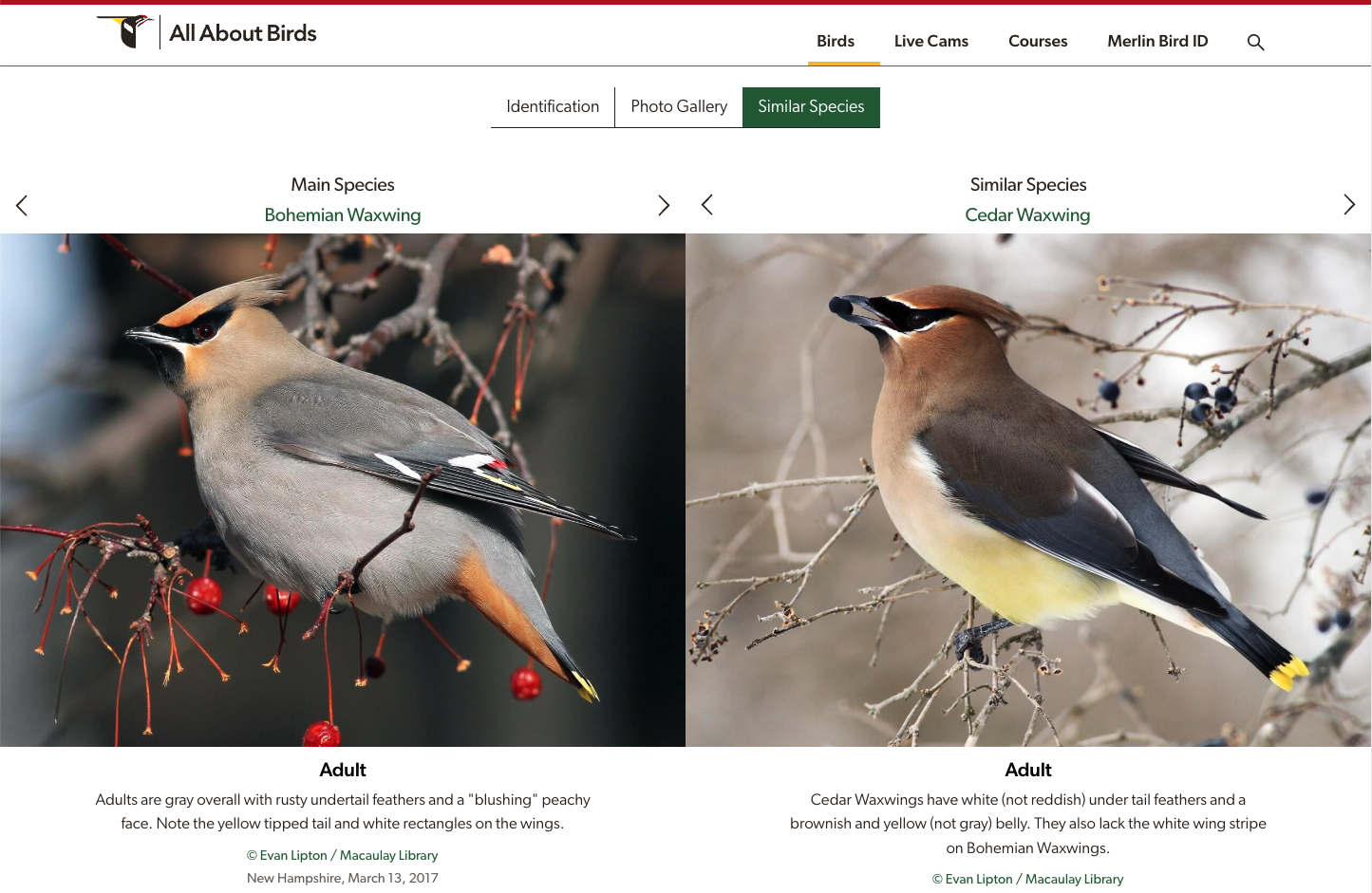
Human Expert Defined Features. We use All About Birds from the Cornell Lab of Ornithology to define human expert-defined features for specific birds. We hire annotators to label these features in accordance to the definitions provided by the website. We use these features to measure alignment between human expert-defined features and learned model features.

Sample Human Expert Defined Features. We show one example image and its associated features for each of the classes in our paper. Also, we have added 10 more classes in our updated dataset! We choose features that are known to be discriminative between other visually similar birds. For example, the Bohemian Waxwing and Cedar Waxwing can be differentiated according to belly color.
Method
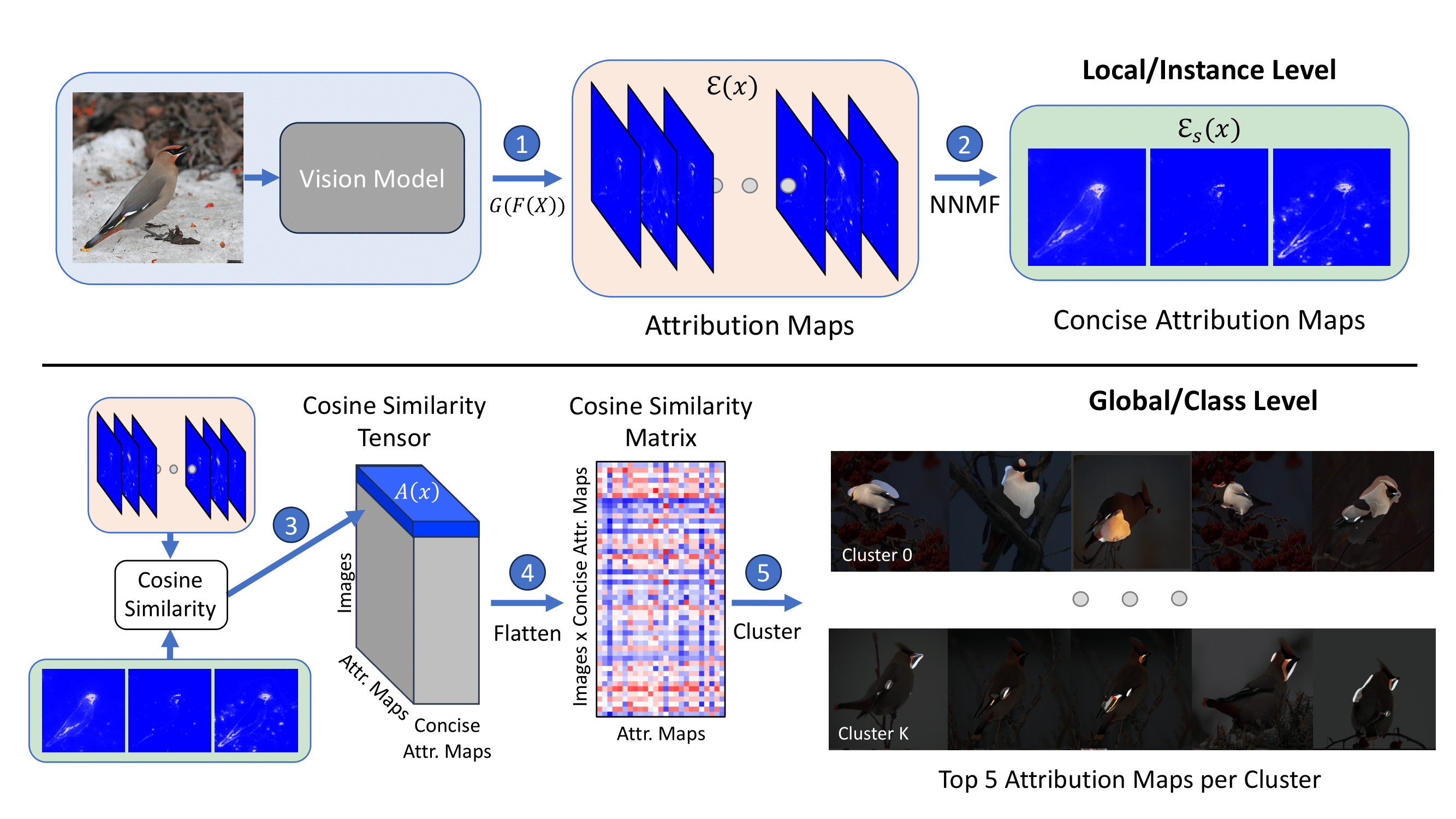
Overview of DCNE. Our method has two stages, the first produces a local/instance level explanation and the second produces a global/class level explanation. The first stage of our method uses non-negative matrix factorization (NMF) to reduce redundancy in the explanations produced by the base XAI method. The second stage clusters images and attributions so that semantically related features within and across images are grouped together.
Results
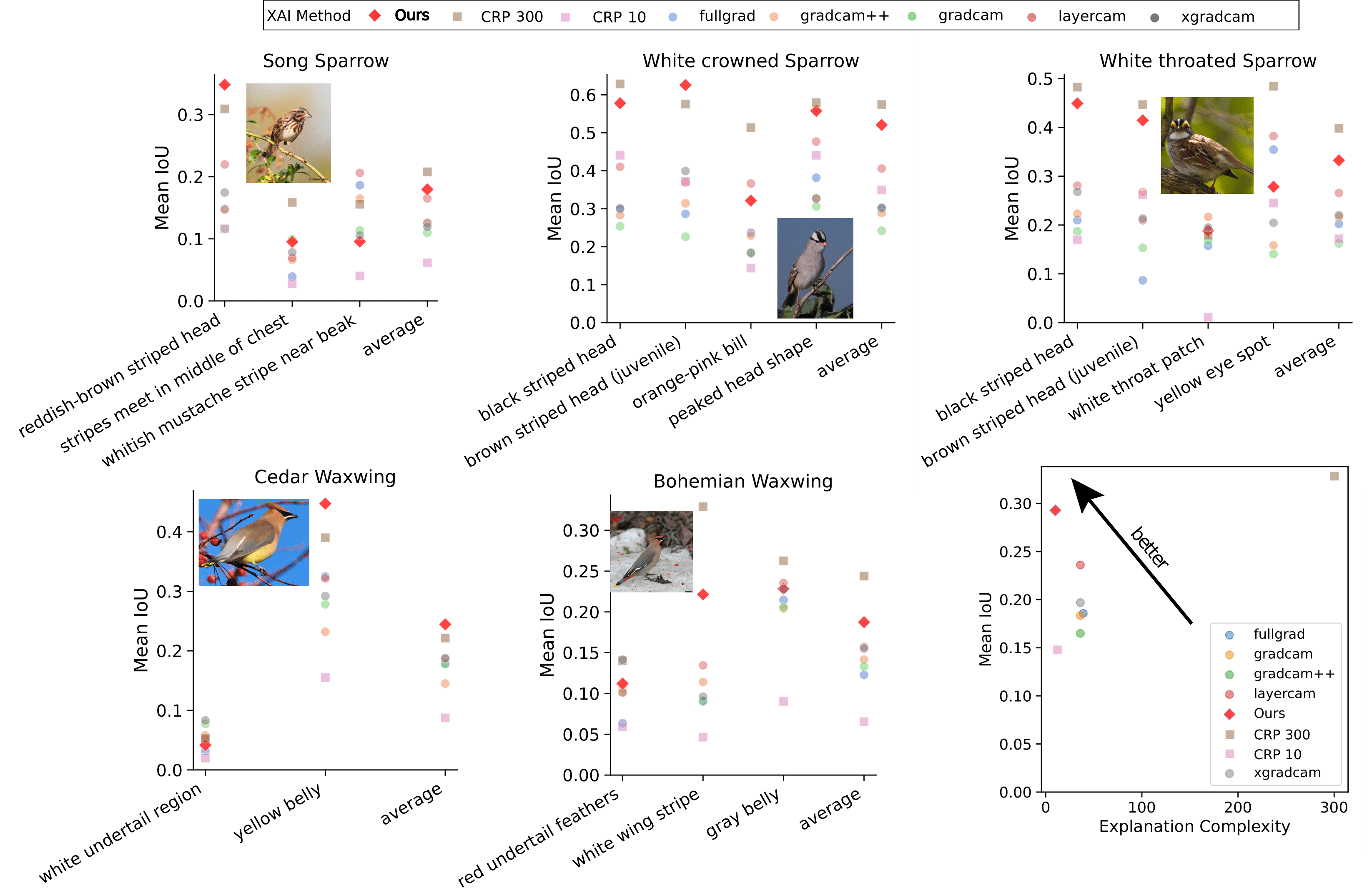
Explanation Complexity vs. Alignment We compare the alignment of the explanations produced by DCNE to those produced by CRP. We find that DCNE produces explanations that are aligned with human expert-defined features while being more concise. We measure alignment using the mean IoU between the best matching attribution maps produced by the model and the human expert-defined features.

Global/Class Level Explanations We find that our global/class level explanations are able to capture semantically related features within and across images. We show five clusters that are particularly easy to interprety. For each cluster we show the five most representative images. We find that this approach is able to show concepts we have in our annotated dataset, but also features that we did not explicitly annotate (but are known to be discriminative).
BibTeX
@inproceedings{kondapaneni2024less,
title={Less is More: Discovering Concise Network Explanations},
author={Kondapaneni, Neehar and Marks, Markus and Mac Aodha, Oisin and Perona, Pietro},
booktitle={ICLR 2024 Workshop on Representational Alignment},
year={2024},
doi={https://doi.org/10.48550/arXiv.2405.15243}
}